Introduction
This post aims to cover the practical and architectural aspects of setting up Behavioural Driven Development (BDD) in a .NET-based web application project which is using an agile methodology.
To put it in oversimplified terms, BDD starts with business requirements defined as features and their associated acceptance criteria. In the popular Cucumber framework, these are usually defined in the Gherkin language and stored in .feature files. Due to the business-readability of Gherkin, these feature files can serve a double duty as both the documentation of business requirements as well as the tests which the developers' software must pass. Instead of developing to tests in a technical language (eg. "when the LoginController receives a request, then the Login view should be served") which offer little business value and really should be the purview of technical staff anyway, software must pass business-readable tests (eg. "when I click the login button, then I am navigated to the login page and a username field is present and a password field is present"). These tests can theoretically be written by business users, although in practice this is still in the domain of the testers. At the very least, this gives a common, easily understandable and common language (or a Domain Specific Language) between developers, testers and business users.
There is a lot of material out there which covers this topic in-depth, here are some excellent posts covering the overall process itself:
Issues
In an agile methodology, software features are delivered in iterations or sprints. In order to assure that new features being introduced do not break any previously developed and verified features, it is important to re-test the software as a whole at each sprint delivery point.
At the bare minimum, the acceptance criteria must be executed manually by testers. We can already see that, in this agile environment, the job of regression testing previously-implemented features gets larger and larger for each sprint. Automation of this regression testing yields massive rewards to catch defects early and prevent the defect list from mounting towards the end of a project. Fortunately, the structured-yet-business-readable Gherkin language lends itself quite well to be converted into executable unit tests, which is where the popular Cucumber framework has come into play over the last decade or so.
Additionally, the aims of BDD are such that the deliverable software is specified, developed and tested against its expected behaviour. In the context of a custom web application, the software's behaviour is primarily driven by user input into a web browser. There are clunky ways to do this with the standard .NET framework, but the most accurate and robust test would be to emulate user actions in an actual web browser. To this end, a robust web driver framework is required such that unit test code can programmatically automate/drive web browser actions.
Architecture
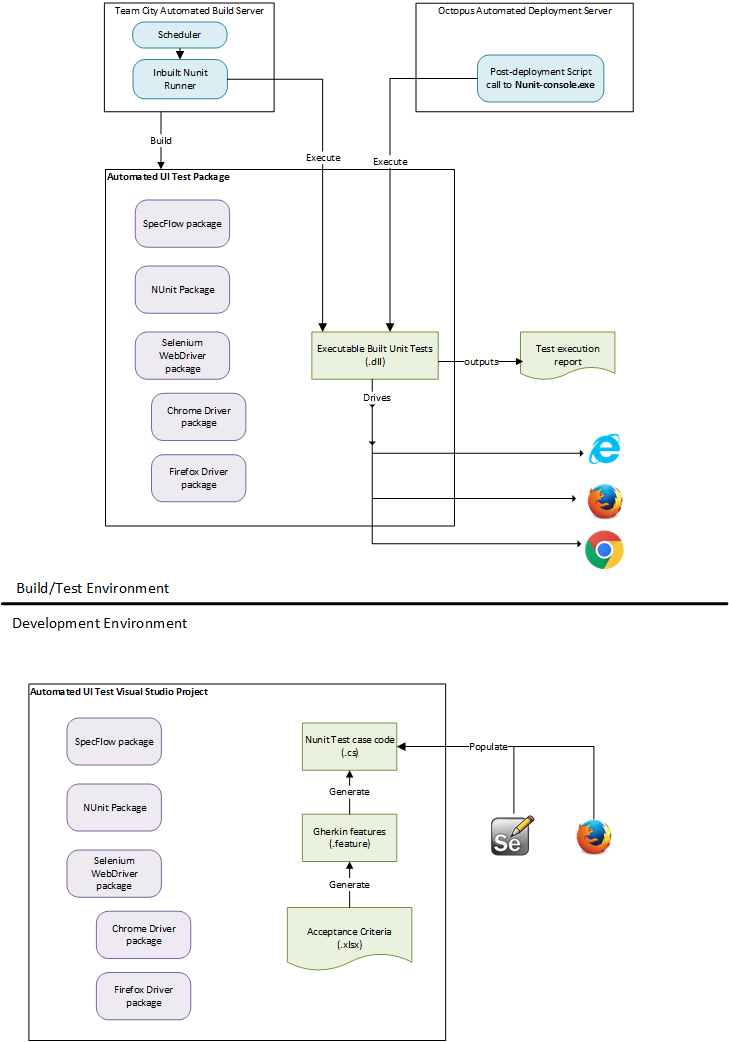
In order to overcome these issues, an automated UI testing framework can be developed with the following components:
- SpecFlow - to consume Gherkin feature files and produce corresponding executable NUnit test methods.
- Selenium - to provide API to automate and drive web browsers when executing NUnit tests.
- Team City - to provide a continuous build environment to build and execute tests. Tests can also be set to execute on a scheduler for regular smoke tests.
- Octopus - to provide deployment component in continuous delivery pipeline. Automated UI tests can be set to execute as a post-deployment process to catch regression defects in a test environment.
Here is a summary of the proposed architecture:
Benefits
The benefits of this solution are manifold:
- With good test coverage, regression testing is performed on the entire software product with minimal effort
- Testers can have more capacity to perform higher-value exploratory testing rather than getting bogged down in things like field-level checks, which are mundane yet repeatable (and thus ideal candidates to be automated) tasks
- Defects are caught much earlier in the development cycle, reducing costs of bug fixing later in the project
Note that this post is not advocating this solution as a one-size-fits-all approach, nor is this solution and tooling specifically tied to BDD; BDD is a more of a conceptual practice rather than a technical one. This solution addresses the issues of regression testing a web application project and fitting in with a BDD project.
Below, we will explore the specific tools.
SpecFlow
SpecFlow the official .NET implementation of Cucumber and is able to convert Gherkin language acceptance criteria into executable unit tests. This is the main technical component which bridges the gap between the testers and developers.
SpecFlow can be added as a NuGet package (source) to a Visual Studio project. The project will hold the acceptance criteria feature files written by testers as *.feature files. SpecFlow will then generate corresponding empty unit tests for the test engineer to complete. These unit tests can then be executed by a supported unit test provider just like any other unit tests, with the difference being mainly that these tests are specified around the Given, When, Then framework of the Gherkin features.
SpecFlow has built-in functionality to produce a comprehensive test execution report on each run. This can be scripted/automated to be sent to key stakeholders after each run.
Excel Integration
SpecFlow comes with a plugin called SpecFlow+ Excel, which allows integration with Excel such that it can pull acceptance criteria and acceptance criteria input data (ie. Examples in the Gherkin language) into feature files and thus generate corresponding test cases.
This becomes extremely handy in a software project which contains an integration component, where many fields may need to be mapped as inputs and outputs across multiple systems. These field properties and mappings may be stored in a data dictionary which forms the source of truth of field-level requirements for the entire team and is stored in a centralised location (perhaps on a SharePoint installation).
As NUnit generates and detects test cases on build of the Visual Studio project, it becomes important to update the referenced Excel file when the centralised data dictionary is updated. This can become cumbersome and error-prone, however it is possible to catch such errors using a pre-build event call to a script to download the latest copy of the data dictionary. SpecFlow will generate the unit test code with a default body of
ScenarioContext.Current.Pending();
which will essentially mark the test result as "inconclusive".
Selenium
Selenium is a suite of browser automation tools. Selenium IDE is a GUI plugin for the Firefox browser (I would give my firstborn for a first-class Chrome equivalent) that's able to record and playback user-interactions in the web browser. Selenium WebDriver is a web browser automation wrapper API which provides a common language to specify web browser behaviour against multiple browsers, thus this provides us with a way to programmatically simulate user behaviour in a web browser.
Selenium WebDriver supports many languages including Python, Perl, PHP, Ruby, Java and C#. Typically, the SpecFlow-generated unit tests will be generated with a name which makes it clear what that method needs to do eg. GivenIClickTheLoginButton(). This can then be populated with code which tells the browser to perform a task eg. programmatically click a button (which is typically found using a CSS selector). This code can be written by hand, however it is possible to use Selenium IDE to record these boiler plate actions as a macro, and then export these macros as C# code to be populated into the generated unit tests. The high-value code typically exists in the Then statements which do the actual test assertions - it is these which need careful attention.
It is evident from the above that the test engineer needs to:
- Have a strong development background
- Have a good knowledge of HTML, CSS and how web code typically works
- Have a close relationship with the web developers to find out IDs and CSS selectors of elements to target
- Have a good knowledge of web automation tools (ie. Selenium)
Team City
https://www.jetbrains.com/teamcity/
Team City is a build automation server and is able to provide continuous integration in a software project to compile code and build packages and run unit tests.
Team City comes with MSTest (the Visual Studio default) and NUnit test runners out-of-the-box. With a SpecFlow project, the good news is that this can be run just like any other NUnit test project - all Team City needs is for all of the project dependencies to be restored. Even with the interactive nature of the tests requiring a GUI, it is possible to run these tests on a Team City build agent which is installed as a windows service.
Octopus
https://octopus.com/Octopus is a deployment automation server and is able to provide managed continuous delivery to deploy software packages to multiple environments.
At Diversus, we have typically used Octopus to control deployments into all pre-production and production environments, including all test and Systems Integration Test (SIT) environments.
In order to achieve fully-automated regression testing in the deployment pipeline, it is necessary to be able to trigger these regression tests automatically and immediately after a deployment to test the entire deployment package as a whole. Fortunately, Octopus provides a script process, so it's just a matter of creating a PowerShell script to call nunit-console.exe on your automate UI test package and setting this step as one of the final steps in an Octopus deployment (there may be other steps required to report on success of the deployment, send test execution reports to stakeholders etc.).
Up Next...
This post aims to introduce the tools, architecture and basic concepts to achieve automated UI regression testing in a continuous delivery pipeline. The tools highlighted above come with extensive documentation, each of which warrant their own investigation. The tools have their own targeted use cases but are all required in order to achieve a near-fully automated continuous delivery pipeline.
In Part 2 of this blog series, we will explore an example implementation of the above architecture.